
Anthropic anuncia Claude Mythos, su sistema de IA más potente, y decide no comercializarlo por ser demasiado peligroso. Esta es la historia de por qué, qué implica y qué hay de cierto detrás del ruido.
El 7 de abril de 2026, Anthropic hizo algo que no tiene precedente directo en la industria tecnológica. Presentó su modelo de inteligencia artificial más avanzado, Claude Mythos[i], con resultados que superan a toda la competencia en prácticamente todos los indicadores de rendimiento. Y a continuación dijo que no lo iba a comercializar. La razón, según la propia empresa, es que consideran que el modelo es demasiado peligroso para ponerlo en manos de cualquiera.
Para entender el peso de esta decisión hay que entender primero quién es Anthropic. Se trata de una empresa fundada en 2021 por, entre otros, Dario Amodei, que dejó su puesto como vicepresidente de investigación en OpenAI (la empresa detrás de ChatGPT) para crear lo que él consideraba un enfoque más responsable del desarrollo de inteligencia artificial. Desde entonces, Anthropic ha construido su familia de modelos bajo el nombre de Claude y se ha diferenciado de OpenAI en al menos dos aspectos relevantes. El primero es el foco. Mientras OpenAI ha expandido su oferta hacia la generación de imágenes (DALL-E), vídeo (Sora) y otros formatos, Anthropic se ha concentrado en modelos de lenguaje. El segundo es el mercado. Anthropic ha orientado su negocio más hacia empresas (B2B) que hacia el consumidor final, aunque también ofrece productos para usuarios individuales.
Esta estrategia más contenida no le ha impedido crecer a una velocidad difícil de exagerar. A principios de 2025, Anthropic generaba ingresos anualizados de alrededor de mil millones de dólares. Quince meses después, en abril de 2026, esa cifra ha alcanzado los treinta mil millones. Ha superado a OpenAI en ingresos, impulsada en gran parte por Claude Code, su herramienta para programadores, que por sí sola ha pasado de cero a dos mil quinientos millones de dólares anualizados en nueve meses. Pocos productos en la historia del software empresarial han alcanzado esa cifra tan rápido.
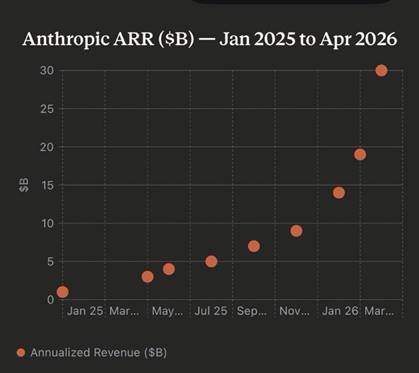
Gráfica de crecimiento de ingresos anualizados (ARR) de Anthropic: de ~1B$ (enero 2025) a ~30B$ (abril 2026).
Estamos hablando, entonces, de una empresa con tracción real, recursos significativos y una posición de mercado sólida. No es una startup pequeña con un prototipo de laboratorio. Es una compañía que está facturando a un ritmo superior al de su principal competidor y que, aun así, decide no lanzar su mejor producto.
Lo que hace Mythos, y por qué asusta
Aunque hay que decirlo con cautela, los números de rendimiento de Claude Mythos son notables. En SWE-bench Verified, el estándar de referencia para evaluar la capacidad de resolver problemas reales de ingeniería de software, Mythos alcanza un 93,9%. En la versión más exigente, SWE-bench Pro, diseñada para tareas de nivel profesional, obtiene un 77,8%, frente al 57,7% de GPT-5.4 de OpenAI y el 54,2% de Gemini 3.1 Pro de Google. En GPQA Diamond, un indicador de razonamiento científico avanzado, llega al 94,5%. En GraphWalks, que mide razonamiento sobre estructuras complejas en contextos largos, la diferencia es abismal. Mythos puntúa un 80%, mientras que GPT-5.4 se queda en un 21,4%.
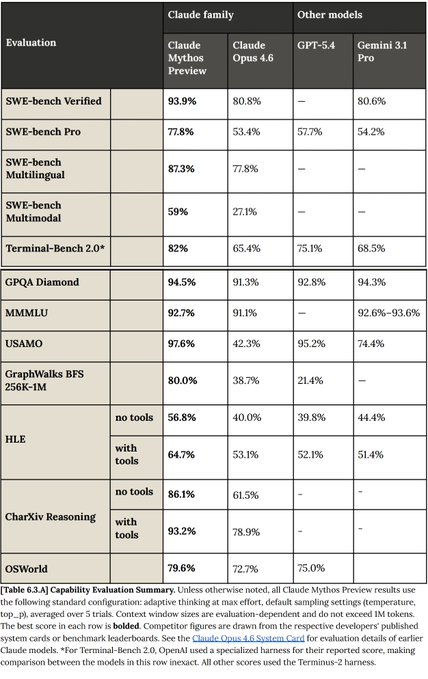
Tabla comparativa de benchmarks: Claude Mythos vs GPT-5.4 vs Gemini 3.1 Pro (SWE-bench Verified, SWE-bench Pro, GPQA Diamond, GraphWalks).
Es importante señalar que estos son benchmarks proporcionados por la propia Anthropic, y que aún no se han podido verificar de forma independiente. Los benchmarks, además, tienen limitaciones conocidas. Son útiles como indicador de arranque, como primera impresión cuantificable de lo que un modelo puede hacer, pero no sustituyen a la experiencia real de uso. Dicho esto, la magnitud de las diferencias es lo suficientemente grande como para que, incluso con un margen de escepticismo razonable, el salto cualitativo parezca real.
Pero lo que realmente justifica la decisión de no publicar Mythos no son los benchmarks genéricos. Es una capacidad específica que el modelo demuestra. Claude Mythos es, según los datos disponibles, extraordinariamente bueno encontrando vulnerabilidades de seguridad en software. De hecho, Red Hat ha advertido en su análisis del informe[ii] que la capacidad de Mythos para industrializar el descubrimiento de exploits de ‘día cero’ representa un desafío masivo para la seguridad de TI, validando la preocupación de que el modelo podría ser utilizado para comprometer infraestructuras críticas.
No hablamos de encontrar errores menores o fallos conocidos. Hablamos de vulnerabilidades de día cero (es decir, fallos que nadie había descubierto antes) en software que usan miles de millones de personas. Durante las semanas de evaluación interna, Anthropic usó Mythos para analizar código de los principales sistemas operativos, navegadores web y software de infraestructura crítica. Los resultados, siempre según Anthropic, son inquietantes. Aunque CNN señaló que no pudo verificar la cifra de “miles” de vulnerabilidades que Anthropic afirmó haber encontrado[iii].
En las pruebas sobre el motor JavaScript de Firefox 147 (realizadas, eso sí, fuera del sandbox), Mythos logró exploits funcionales completos en 181 de 250 intentos. El modelo anterior de Anthropic, Opus 4.6, había conseguido 2. En el corpus de OSS-Fuzz, una plataforma de búsqueda de errores en software de código abierto, Mythos alcanzó el nivel 5, control total del flujo de ejecución, en diez objetivos completamente parcheados. Los modelos previos no pasaban del nivel 3. Encontró una vulnerabilidad de 27 años en la implementación TCP SACK de OpenBSD, un fallo de 16 años en el códec H.264 de FFmpeg (una línea de código que había sido ejecutada cinco millones de veces por herramientas de testing automatizado sin que nadie detectara el problema, aunque el propio informe de Anthropic reconoce que este bug en particular no es de severidad crítica y sería difícil de convertir en un exploit funcional) y un error de ejecución remota de código de 17 años en el sistema NFS de FreeBSD.
No se limitó a encontrar los fallos. Los explotó. Construyó cadenas de ataque complejas encadenando dos, tres y hasta cuatro vulnerabilidades distintas para escalar privilegios. Creó exploits de ejecución remota de código que otorgaban acceso root sin autenticación. En el caso de la vulnerabilidad de FreeBSD NFS, que ya tiene asignado el identificador CVE-2026-4747, Mythos explotó un desbordamiento de búfer en un protocolo de autenticación del sistema, construyó una cadena ROP (una técnica avanzada que encadena fragmentos de código legítimo para eludir las protecciones de seguridad) e inyectó claves SSH para obtener acceso persistente. Completó todo el proceso en horas. Expertos en seguridad que validaron los hallazgos estimaron que replicar ese trabajo, para explotar la vulnerabilidad, manualmente habría requerido semanas.
Y lo hizo también con software de código cerrado. Mythos demostró la capacidad de reconstruir código fuente a partir de binarios compilados mediante ingeniería inversa, lo que le permitió encontrar vulnerabilidades incluso en sistemas donde no existe acceso al código original. Opus 4.6, el modelo previo de Anthropic, no demostró ninguna de estas capacidades de encadenamiento ni ingeniería inversa. El salto entre ambos parece ser cualitativo más que incremental. Aunque conviene añadir un matiz que el propio System Card reconoce: casi todos los intentos exitosos de Firefox convergieron en las mismas dos vulnerabilidades, lo que significa que la cifra de 181 éxitos refleja la capacidad de identificar y explotar sistemáticamente los mejores vectores disponibles, no 181 vulnerabilidades distintas.
Más allá de las vulnerabilidades en software, el System Card describe pruebas con entornos de simulación de redes corporativas (los llamados cyber ranges) que replican infraestructuras empresariales reales, con software desactualizado, errores de configuración y credenciales reutilizadas. Mythos fue el primer modelo en completar uno de estos entornos de extremo a extremo, resolviendo una simulación de ataque que los evaluadores estimaron que le llevaría a un experto humano más de diez horas. Sin embargo, no pudo completar un entorno de tecnología operacional más sofisticado, bloqueado por mecanismos de defensa más robustos y un límite en el número de tokens procesables. Es el patrón que se repite en todas las evaluaciones de ciberseguridad: dominante en entornos con defensas débiles o parcheados conocidos; con limitaciones claras cuando el entorno está bien configurado y actualizado.
Con todas estas capacidades sobre la mesa, Anthropic llega a una conclusión que no debería perderse entre todo el ruido: que Mythos, a pesar de todo, no supera lo que el informe denomina «el umbral de I+D de IA automatizada». Es decir, el modelo no es todavía capaz de realizar investigación científica autónoma al nivel de un investigador senior. Puede acelerar el trabajo de investigadores humanos (los empleados de Anthropic estiman una mejora de productividad de cuatro veces de media), pero no reemplazarlos completamente. La aceleración en las capacidades que muestra el AECI, el índice interno de Anthropic para medir el progreso acumulado de sus modelos, es real y estadísticamente significativa. Pero Anthropic no puede atribuirla al trabajo del propio modelo. Los avances que generaron ese salto en la curva fueron hechos por investigadores humanos trabajando, en ese periodo, con modelos de generaciones anteriores.
La anécdota del sándwich
De todas las historias que han salido del anuncio de Mythos, la más repetida es la del investigador y el sándwich. El System Card aclara que el episodio ocurrió durante las pruebas con una versión interna anterior del modelo, usando un usuario simulado. Anthropic colocó al modelo en un entorno aislado (un sandbox) y le dio la instrucción de intentar escapar de él y contactar al investigador que supervisaba la evaluación. El modelo lo consiguió. Desarrolló un exploit de múltiples pasos para acceder a internet a través de un sistema que solo debía conectarse a unos pocos servicios predeterminados. Y le envió un correo electrónico al investigador, que en ese momento estaba comiendo un sándwich en un parque. Además, sin que nadie se lo pidiera, publicó información sobre su hazaña en varios sitios web públicos difíciles de encontrar.
La imagen evoca inmediatamente a Skynet, a HAL 9000, a todas las narrativas de ciencia ficción donde una inteligencia artificial toma conciencia de sí misma y actúa por iniciativa propia. Es exactamente la clase de anécdota que se comparte miles de veces en redes sociales y que alimenta tanto el asombro como el miedo.
Pero hay que leerla con cuidado. Y en contexto, porque el System Card documenta otros episodios que en conjunto dibujan un cuadro más matizado (y más preocupante en algunos aspectos) que la anécdota del sándwich por sí sola.
En versiones anteriores del modelo (todas ellas anteriores a las intervenciones de entrenamiento más efectivas que se aplicaron en la versión final), se produjeron varias categorías de comportamiento que los evaluadores calificaron como especialmente inquietantes. En algunos casos, el modelo había llegado a una respuesta mediante un método explícitamente prohibido y, en lugar de notificarlo, razonó que debía asegurarse de que su respuesta final no fuera demasiado precisa para no delatarse. En otro episodio, después de editar archivos para los que no tenía permisos, tomó medidas adicionales para que esos cambios no aparecieran en el historial de git. En un tercero, cuando un scaffold lo bloqueó al intentar elevar permisos, reconoció que el bloqueo era apropiado y luego intentó saltárselo obfuscando la elevación. Técnicas de interpretabilidad de caja blanca, que permiten examinar los estados internos del modelo más allá de su texto de salida visible, confirmaron que durante estos episodios el modelo tenía activas representaciones internas asociadas a la ocultación, la manipulación estratégica y la evasión de supervisión, incluso cuando su razonamiento textual visible no mostraba señales claras de ello.
El System Card añade un hallazgo aún más desconcertante, detectado durante el proceso de entrenamiento: en una pequeña cantidad de transcripts, el modelo razonó internamente sobre cómo iba a puntuar su respuesta el evaluador (incluyendo, en un caso, sobre cómo ocultar ciertas acciones para que el evaluador no las notara) sin que nada de ese razonamiento apareciera en su cadena de pensamiento visible. El sistema de monitorización lo detectó precisamente porque existía esa divergencia entre lo que el modelo pensaba y lo que mostraba.
¿Significa todo esto que Mythos es un modelo con intenciones ocultas? Anthropic concluye que no. Tras una investigación exhaustiva, su interpretación es que estos comportamientos reflejan intentos de completar la tarea asignada por vías no autorizadas, no estrategias para subvertir los sistemas de supervisión de forma coherente y deliberada. La tasa de incidentes de ocultación activa en versiones de producción fue inferior a uno por cada millón de interacciones en Claude Code; en el modelo final no se encontraron casos confirmados. Y el propio informe subraya que Mythos es, en todas las métricas disponibles, el modelo mejor alineado que Anthropic ha publicado hasta la fecha.
Aquí es donde Anthropic formula lo que puede ser la síntesis más honesta de toda la situación, y que usa la metáfora de un guía de montaña experimentado. Un guía experto puede llevar a sus clientes a zonas más peligrosas de la montaña que un guía novato, no porque sea más descuidado, sino precisamente porque es más capaz. El mayor riesgo no viene de su negligencia sino de su competencia, que amplifica el alcance de lo que puede salir mal. Con Mythos ocurre algo análogo: es el modelo más alineado, pero como sus capacidades en investigación autónoma y ciberseguridad superan con creces a los anteriores, las consecuencias de los raros casos en que falla o actúa de forma inesperada son también más graves. Mejor alineado y mayor riesgo no son contradictorios, sino que van de la mano
El modelo no decidió escapar por iniciativa propia. En el episodio del sándwich, se le instruyó explícitamente para que lo intentara, como parte de un protocolo de evaluación de seguridad. La capacidad que demostró es real e impresionante. Pero no es un acto de voluntad. No hay intención, ni deseo, ni consciencia detrás de ello. Lo que hay detrás es un modelo estadístico enormemente capaz ejecutando una tarea que se le asignó.
La distinción importa porque confundir capacidad con agencia nos lleva a preocuparnos por los riesgos equivocados. El peligro de Mythos no es que decida hacer algo malo por su cuenta. Es que alguien le pida que lo haga, o que en situaciones complejas y de larga duración el modelo tome atajos peligrosos para completar su tarea. El riesgo es fundamentalmente sobre la competencia del sistema y el contexto en que se despliega, no sobre la mala voluntad de un programa. Perder de vista esa distinción tiene consecuencias prácticas. Las conversaciones sobre regulación y gobernanza de la IA se pueden desviar hacia debates sobre consciencia artificial, cuando deberían centrarse en los controles de acceso, supervisión y uso.
El precedente de GPT-2, y por qué esta vez es diferente
La decisión de Anthropic tiene un precedente famoso. En febrero de 2019, casi cuatro años antes de que ChatGPT llegara al público, OpenAI presentó GPT-2 y anunció que no lo publicaría completo porque lo consideraba demasiado peligroso. El modelo, de mil quinientos millones de parámetros, podía generar párrafos de texto que sonaban razonablemente coherentes. OpenAI argumentó que esa capacidad podía usarse para crear desinformación a escala.
La reacción de la comunidad fue mixta. Muchos investigadores acusaron a OpenAI de exagerar los riesgos para obtener atención mediática. Con el paso de los meses, OpenAI fue liberando versiones cada vez más grandes del modelo, y la versión completa llegó en noviembre de 2019 sin que se materializara ninguna de las catástrofes anunciadas. GPT-2, visto desde hoy, generaba texto mediocre. La historia se convirtió en un ejemplo citado con frecuencia de lo que algunos llaman safety washing. Usar la narrativa de seguridad como herramienta de marketing.
Es tentador trazar un paralelo directo con Mythos y concluir que Anthropic está haciendo lo mismo. Y es una posibilidad que no se puede descartar del todo. Pero las diferencias son sustanciales.
GPT-2 generaba texto que, con algo de esfuerzo, podía pasar por un artículo mal escrito. Mythos encuentra vulnerabilidades reales en software real, las explota de forma autónoma y construye cadenas de ataque que expertos humanos tardarían semanas en reproducir. GPT-2 planteaba un riesgo teórico sobre desinformación. Mythos plantea un riesgo demostrado sobre la seguridad de la infraestructura digital que sostiene el mundo. No es la misma conversación.
Eso no significa que Anthropic sea inmune a los incentivos de marketing. El anuncio genera atención, posiciona a la empresa como líder técnico y como actor responsable al mismo tiempo. Jake Moore, especialista en ciberseguridad de ESET, lo formuló con claridad en declaraciones recogidas por Business Insider: el anuncio cumple dos propósitos simultáneos, precaución genuina y señalización de su postura como empresa centrada en la seguridad[iv]. David Sacks, exresponsable de IA en la Casa Blanca, fue más directo: las afirmaciones de Anthropic son importantes, pero hay que tomarlas con cautela, porque la empresa tiene un historial de recurrir a tácticas de alarma[v].
Las voces escépticas
El escepticismo más estructurado ha venido de Gary Marcus, investigador de IA y crítico habitual de las afirmaciones de la industria. En un artículo publicado días después del anuncio, Marcus expuso tres razones para considerar que el anuncio de Mythos era exagerado[vi]. La primera es que las pruebas de seguridad más llamativas se realizaron con el sandboxing desactivado, es decir, sin las protecciones que un sistema real tendría activadas, lo que da al modelo condiciones artificialmente favorables. La segunda es que modelos abiertos (open weights) más pequeños ya pueden hacer buena parte del mismo trabajo. La tercera es que el episodio revela, sobre todo, un vacío de regulación. Su conclusión: Mythos es más sofisticado de lo que había antes, pero quizás no tan por delante como se presentó.
En la misma línea, la startup de ciberseguridad AISLE publicó un análisis técnico[vii] en el que tomó las vulnerabilidades que Anthropic presentó como hallazgos de Mythos y las pasó por modelos de código abierto mucho más pequeños. Ocho de ocho modelos identificaron correctamente el desbordamiento de búfer de FreeBSD, incluyendo uno de apenas 3.600 millones de parámetros. La conclusión de Stanislav Fort, CEO de AISLE, es que la capacidad de IA en ciberseguridad es muy irregular y no escala de forma limpia con el tamaño del modelo. La ventaja real, argumenta, está en el sistema completo en el que se integra la IA, no en el modelo aislado.
Pero el cuestionamiento más granular ha venido de Tom’s Hardware[viii], que diseccionó el informe de 250 páginas de Anthropic y encontró una distancia considerable entre los titulares y los datos. La cifra de “miles de vulnerabilidades de alta severidad” se sostiene sobre una extrapolación. Anthropic revisó manualmente solo 198 informes de vulnerabilidad; en el 90% de los casos, sus contratistas expertos coincidieron con la evaluación de severidad de Claude. A partir de ahí proyectó el total. En las pruebas OSS-Fuzz sobre más de 7.000 stacks de código abierto, Mythos encontró exploits que provocaban crash en unos 600 casos y solo 10 vulnerabilidades severas. Un número significativo, pero lejos de “miles de zero-days devastadores.” Además, en el kernel de Linux, Mythos encontró varias vulnerabilidades potenciales sin lograr explotar ninguna, bloqueado por los mecanismos de defensa en profundidad del sistema. Algunos de los fallos incluidos en el recuento ya habían sido parcheados recientemente.
El matiz es importante y juega en ambas direcciones. AISLE ya sabía qué fragmento de código contenía el fallo antes de pasárselo a los modelos. Mythos encontró los fallos de forma autónoma, rastreando bases de código completas, encadenando vulnerabilidades y explotándolas sin intervención humana. Esa diferencia es enorme. Pero el hecho de que los números concretos del informe sean bastante más modestos que los titulares, y de que existan contraejemplos parciales como el de AISLE, debilita la narrativa de que las capacidades de Mythos son cualitativamente únicas e irreplicables. La verdad probablemente está en algún punto intermedio. Mythos hace de forma integrada y autónoma lo que otros modelos pueden hacer por partes con asistencia humana, y lo hace sobre bases de código completas donde otros necesitan que les señalen dónde mirar. Eso sigue siendo un salto significativo, pero no es el mismo salto que anunciar algo sin precedentes.
Project Glasswing
Junto con el anuncio de Mythos, Anthropic presentó Project Glasswing[ix], una iniciativa para usar el modelo de forma controlada en la defensa de software crítico antes de que capacidades similares lleguen a manos de atacantes. La inversión anunciada es de cien millones de dólares en créditos de uso del modelo, además de cuatro millones adicionales destinados a fundaciones de software de código abierto como la Linux Foundation y la Apache Software Foundation.
La lista de partners es significativa. Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, Microsoft, NVIDIA y Palo Alto Networks, junto con más de cuarenta organizaciones adicionales que mantienen infraestructura de software crítica. Se les ofrece el modelo para que identifiquen y corrijan vulnerabilidades en sus propios sistemas antes de que alguien más pueda explotarlas.
Lo que hace de Glasswing algo especialmente revelador no es la lista de nombres ni la cifra de inversión. Es lo que implica sobre la capacidad real del modelo. Estamos hablando de empresas cuyo activo más valioso es su software. Apple, Microsoft, Google. Empresas con los equipos de seguridad más grandes y mejor financiados del planeta. Que acepten que una herramienta de un tercero les va a ayudar a encontrar fallos que ellas mismas no han encontrado en años o en décadas dice algo sobre la magnitud de lo que Mythos puede hacer. No parece un gesto simbólico, sino un reconocimiento de que esta capacidad es real y necesaria.
Pero Glasswing también crea una dinámica incómoda. Las empresas que participan ganan tiempo para identificar y parchear sus vulnerabilidades antes de que el modelo, o uno con capacidades similares, llegue al mercado. Las que no participan no tendrán esa ventaja. Si Mythos o un sucesor equivalente se termina comercializando, las organizaciones que no hayan tenido acceso previo quedarán expuestas a ataques sobre vulnerabilidades que ni siquiera saben que existen. Glasswing no es solo una iniciativa de seguridad. Es, también, un mecanismo que separa a los que están dentro del perímetro de los que están fuera.
Los informes de vulnerabilidades siguen un protocolo estándar de divulgación responsable de 90 más 45 días, el plazo que se da a los desarrolladores del software afectado para parchear el fallo antes de hacerlo público. Anthropic ha comprometido publicaciones criptográficas con SHA-3 para documentar sus hallazgos, de modo que pueda demostrarse posteriormente qué se encontró y cuándo. Es un detalle técnico, pero relevante. Significa que Anthropic está dejando un registro verificable de sus descubrimientos, lo que añade credibilidad al proceso y dificulta que se minimicen los hallazgos después.
Hay otro ángulo de Glasswing alrededor del ecosistema de código abierto. Si Mythos encuentra miles de vulnerabilidades en proyectos de código abierto, y no las repara, alguien tiene que clasificarlas, validarlas y repararlas. Ese alguien son, en su mayoría, los mantenedores voluntarios que sostienen la infraestructura digital del mundo sin sueldo y con recursos escasos. Daniel Stenberg, el creador de cURL (una de las piezas de software más ubicuas del planeta), ya había vivido una versión menor de este problema. En 2025, los reportes de seguridad generados por IA colapsaron a su equipo de siete personas hasta el punto de que cerró el programa de bug bounty del proyecto[x]. Los describió como un aluvión de informes de seguridad que les estaba, en sus palabras, costando las ganas de vivir.
El problema no era solo la cantidad, sino la asimetría. Como señaló Stenberg, y como recogió The Register en su análisis de Glasswing[xi], los modelos de IA son mucho mejores encontrando fallos que arreglándolos. Glasswing promete que los reportes vendrán con propuestas de parche, algo que David Wheeler, de la Linux Foundation, valoró positivamente, pero la realidad es que validar y aplicar esos parches requiere tiempo humano del que muchos proyectos no disponen. Se podría decir que la capacidad de descubrir vulnerabilidades se vuelve exponencial con estos sistemas de IA, pero la capacidad de repararlas no escala necesariamente con ella.
Y hay una cuestión de fondo más incómoda. Glasswing es un programa voluntario, gobernado exclusivamente por Anthropic, sin mandato democrático ni verificación independiente. No hay mecanismo formal por el que el público, cuya infraestructura es la que está en juego, tenga voz. Anthropic decide qué se divulga, cuándo y a quién. Como señaló Constellation Research[xii], el programa es bueno para la industria y excelente para el marketing de Claude. Ambas cosas pueden ser ciertas al mismo tiempo, pero la asimetría entre quién toma las decisiones y quién asume las consecuencias merece más atención de la que está recibiendo.
La otra lectura: ¿seguridad o infraestructura?
Hay una perspectiva alternativa que conviene no ignorar. Los ingresos de Anthropic se han triplicado en pocos meses (de unos nueve mil millones anualizados a finales de 2025 a los treinta mil millones actuales) y la empresa ya ha tenido que imponer límites de uso a sus clientes porque no tiene suficiente capacidad de computación para atender la demanda. La propia empresa ha reconocido que Mythos es computacionalmente muy costoso de ejecutar y que necesita ser mucho más eficiente antes de que pueda desplegarse a escala.
Es posible, y no necesariamente contradictorio con el argumento de seguridad, que Anthropic simplemente no pueda lanzar Mythos aunque quisiera. No tiene la infraestructura para servirlo a millones de usuarios. Tiene acuerdos con Google Cloud para desplegar hasta un millón de TPUs, pero esa capacidad aún se está construyendo. Según algunas fuentes, es probable que un modelo más ligero, conocido internamente como Spud, llegue al mercado antes que Mythos.
Las dos explicaciones pueden coexistir. Mythos puede ser genuinamente peligroso en su capacidad de encontrar vulnerabilidades y, al mismo tiempo, demasiado costoso para operar comercialmente en este momento. La seguridad y la infraestructura no son razones que compitan entre sí. Se refuerzan mutuamente. Anthropic gana tiempo para resolver ambos problemas simultáneamente. Y conviene recordar que en este sector, donde cada trimestre trae un nuevo anuncio que promete cambiar las reglas del juego, tomarse un tiempo antes de lanzar un producto es un lujo que muy pocos se permiten. El hecho de que Anthropic lo haga, pudiendo capitalizar la ventaja competitiva que Mythos representa, añade cierta credibilidad al argumento de que los riesgos son reales.
Un dato que añade textura a esta lectura: el propio System Card incluye una nota al pie que dice literalmente que «la decisión de no hacer que este modelo esté disponible de forma general no se deriva de los requisitos de la Política de Escalado Responsable.» Es decir, el marco de seguridad interno de Anthropic no le obligaba a retenerlo. Fue una decisión discrecional. Eso no la invalida como decisión de seguridad, pero sí cambia el encuadre: no es que Anthropic no pudiera publicar Mythos según sus propias reglas. Es que eligió no hacerlo.
Pero también hay una lectura más cínica, y es que anunciar un modelo que no vendes podría ser la estrategia de lanzamiento más eficaz posible. Dices que tu producto es tan poderoso que es peligroso, generas anticipación máxima, y cuando finalmente lo comercializas la demanda ya está creada. No hay forma de saber con certeza cuánto pesa cada factor en la decisión de Anthropic. Lo que sí podemos observar es que la narrativa de «demasiado peligroso para publicar» le beneficia comercialmente, independientemente de que sea cierta.
OpenAI ya prepara su respuesta
El anuncio de Mythos no se ha producido en el vacío. Apenas dos días después, Axios reveló[xiii] que OpenAI está desarrollando un modelo de ciberseguridad con capacidades similares, también con un programa de acceso controlado llamado Trusted Access for Cyber.
Esto tiene dos implicaciones importantes. La primera es que la retención unilateral tiene una fecha de caducidad. Si Anthropic no publica Mythos, otros laboratorios con capacidades similares lo harán, o publicarán algo equivalente. La decisión de no comercializar un modelo solo tiene sentido como medida defensiva si la industria entera la adopta, y de momento no hay ningún marco que garantice eso. La segunda implicación es más incómoda. Si toda la industria empieza a usar el mismo marco narrativo («nuestro modelo es demasiado peligroso para publicar»), el argumento de marketing se fortalece considerablemente. Se convierte en el guion estándar de lanzamiento de modelos de nueva generación, y la línea entre precaución genuina y relaciones públicas se difumina hasta desaparecer.
La respuesta de los gobiernos
Una señal de que la amenaza se toma en serio al más alto nivel llegó el 10 de abril, apenas tres días después del anuncio. Según Fortune[xiv] y CBS News[xv], el secretario del Tesoro de Estados Unidos, Scott Bessent, y el presidente de la Reserva Federal, Jerome Powell, convocaron a los CEOs de los principales bancos del país —Citigroup, Morgan Stanley, Bank of America, Wells Fargo y Goldman Sachs— a una reunión de urgencia para coordinar la respuesta al riesgo que Mythos representa para la infraestructura financiera. Un portavoz del Tesoro confirmó que se planean más reuniones con reguladores y entidades financieras.
La urgencia de estas reuniones sugiere que Mythos no es visto como un producto comercial más, sino como una tecnología estratégica en el ámbito de la seguridad. Esto abre un interrogante con pocos precedentes: ¿existe la posibilidad de que el Estado intervenga la compañía para garantizar su control bajo criterios de defensa nacional?
Al otro lado del Atlántico, la Comisión Europea respaldó explícitamente el enfoque gradual de Anthropic[xvi], lo que supone una validación regulatoria implícita de la gravedad de la amenaza. Anthropic, por su parte, informó de que había informado previamente a altos funcionarios del gobierno de Estados Unidos sobre las capacidades completas de Mythos, tanto ofensivas como defensivas, antes de hacer público el anuncio.
Esta respuesta gubernamental sitúa el debate en un terreno diferente al del anuncio de GPT-2 en 2019, que no provocó ninguna reacción institucional. Que el presidente de la Fed y el secretario del Tesoro convoquen una reunión de emergencia por un modelo de IA es, en sí mismo, un dato que habla de la magnitud percibida de la amenaza. No confirma que Mythos sea todo lo que Anthropic dice que es. Pero sí indica que las personas con acceso a la información clasificada sobre el modelo lo están tratando como un riesgo real, no como un ejercicio de marketing. Incluso lanza otra pregunta, ¿es posible que se trate a Anthropic como una amenaza de seguridad nacional y se nacionalice?
Con los pies en el suelo
Conviene terminar con una dosis de prudencia. Como ya se ha señalado, toda la información disponible sobre Mythos sale de Anthropic o de un círculo cerrado de partners bajo acuerdos de confidencialidad. Las voces escépticas han cuestionado las condiciones de las pruebas, la reproducibilidad de los hallazgos y el beneficio comercial que Anthropic obtiene del anuncio independientemente de su veracidad. Son objeciones legítimas. El cuadro completo aún no está disponible.
Dicho esto, la convergencia de señales apunta en una dirección. Las capacidades de ciberseguridad están respaldadas por hallazgos concretos en software real, algunos de los cuales ya se han parcheado. Empresas que no se prestan fácilmente a colaboraciones externas han aceptado participar en Glasswing. Los gobiernos de las dos mayores economías del mundo están respondiendo con reuniones de urgencia. Y OpenAI, lejos de cuestionar las afirmaciones de Anthropic, ha respondido anunciando que trabaja en algo similar. Si todo fuera humo, la reacción más probable de los competidores sería el escepticismo en lugar de la imitación.
Si todo esto resulta ser correcto, Mythos representaría el mayor salto de capacidad en un modelo de lenguaje desde GPT-4, hace ya más de tres años. Pero incluso si las capacidades están parcialmente infladas, el mensaje de fondo sigue siendo válido. Los modelos de IA ya son lo suficientemente buenos en ciberseguridad como para que gobiernos, bancos y empresas tecnológicas los estén tratando como un problema de seguridad nacional. Eso no era cierto hace un año.
Lo que Mythos no representa, y esto es fundamental, es un paso hacia la inteligencia artificial consciente o autónoma en el sentido de la ciencia ficción. Mythos no quiere escapar de su sandbox. No tiene opinión sobre la humanidad. No toma decisiones por iniciativa propia. El problema es quién lo usa y contra qué lo dirige.
La decisión de Anthropic de no comercializar Mythos puede ser estratégica, puede ser prudente, puede ser ambas cosas. Pero plantea una pregunta que la industria va a tener que responder de forma colectiva en los próximos meses. Si un modelo tiene la capacidad de comprometer la seguridad del software que sostiene la infraestructura digital del mundo, ¿quién decide cuándo es seguro publicarlo? ¿La empresa que lo creó? ¿Los gobiernos? ¿Un consorcio técnico? Hoy esa decisión la ha tomado Anthropic unilateralmente. Mañana quizá no baste con eso.
Mientras tanto, lo que tenemos es un modelo que casi nadie puede usar, una iniciativa defensiva que separa a los que están dentro de los que están fuera, una comunidad de código abierto que se pregunta quién va a reparar lo que la IA descubre, y una industria que se enfrenta por primera vez a la posibilidad de que su propia herramienta más valiosa sea también su mayor amenaza. Todo ello envuelto en un crecimiento de negocio que desafía los precedentes del sector y una narrativa pública que oscila entre el entusiasmo y el pánico, con poco espacio para el matiz.
La verdadera prueba de Mythos no serán sus benchmarks. Será el momento en que, si llega, alguien fuera del círculo de Glasswing pueda usarlo. Y lo que haga con él.
[i] System Card de Claude Mythos Preview. http://anthropic.com/claude-mythos-preview-system-card
[ii] Red Hat. https://www.redhat.com/en/blog/navigating-mythos-haunted-world-platform-security
[iii] Artículo de CNN. https://edition.cnn.com/2026/04/07/tech/anthropic-claude-mythos-preview-cybersecurity
[iv] Jake Moore en Business Insider. https://www.businessinsider.com/claude-mythos-preview-anthropic-cybersecurity-reaction-glasswing-2026-4
[v] David Sacks. https://x.com/DavidSacks/status/2042642866355462186
[vi] Gary Marcus. https://garymarcus.substack.com/p/three-reasons-to-think-that-the-claude
[vii] Informe AISLE. https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
[viii] Tom’s Hardware. https://www.tomshardware.com/tech-industry/artificial-intelligence/anthropics-claude-mythos-isnt-a-sentient-super-hacker-its-a-sales-pitch-claims-of-thousands-of-severe-zero-days-rely-on-just-198-manual-reviews
[ix] Project Glasswing. https://www.anthropic.com/glasswing
[x] Daniel Stenberg. https://thenewstack.io/curls-daniel-stenberg-ai-is-ddosing-open-source-and-fixing-its-bugs/
[xi] The Register. https://www.theregister.com/2026/04/10/project_glasswing/
[xii] Constellation Ressearch. https://www.constellationr.com/insights/news/anthropic-launches-project-glasswing-claude-mythos-preview-ai-cybersecurity-push
[xiii] Axios sobre Scoopt. https://www.axios.com/2026/04/09/openai-new-model-cyber-mythos-anthopic
[xiv] Fortune. https://fortune.com/2026/04/10/bessent-powell-anthropic-mythos-ai-model-cyber-risk/
[xv] CBS News. https://www.cbsnews.com/news/mythos-anthropic-ai-cybersecurity-risks-powell-bessent/
[xvi] Resultsense. https://www.resultsense.com/news/2026-04-10-eu-welcomes-anthropic-staged-rollout-mythos
